


今天我们要介绍两篇研究论文。其中一篇介绍了一种从文本中构建可查询表格的系统,另一篇介绍了一种生成数据操作任务代码的系统(例如“将‘Path’列中所有内容的结尾截去一个字符”)。虽然我们是从数据湖的角度来看这些问题,但它们也可能会在其他工作负载中遇到,比如网络爬虫。
数据湖通常存储大量非结构化/半结构化数据,例如用户生成的评论、新闻文章、日志、合同文件等。从文本数据中提取价值很难,因为这通常需要一个既懂业务又懂技术的人来进行。像GPT这样的语言模型可以自动化非结构化/半结构化数据的处理流程。此外,它们还可以简化非编程人员的数据操作。
#1. Evaporate-Code+(Arora等人)
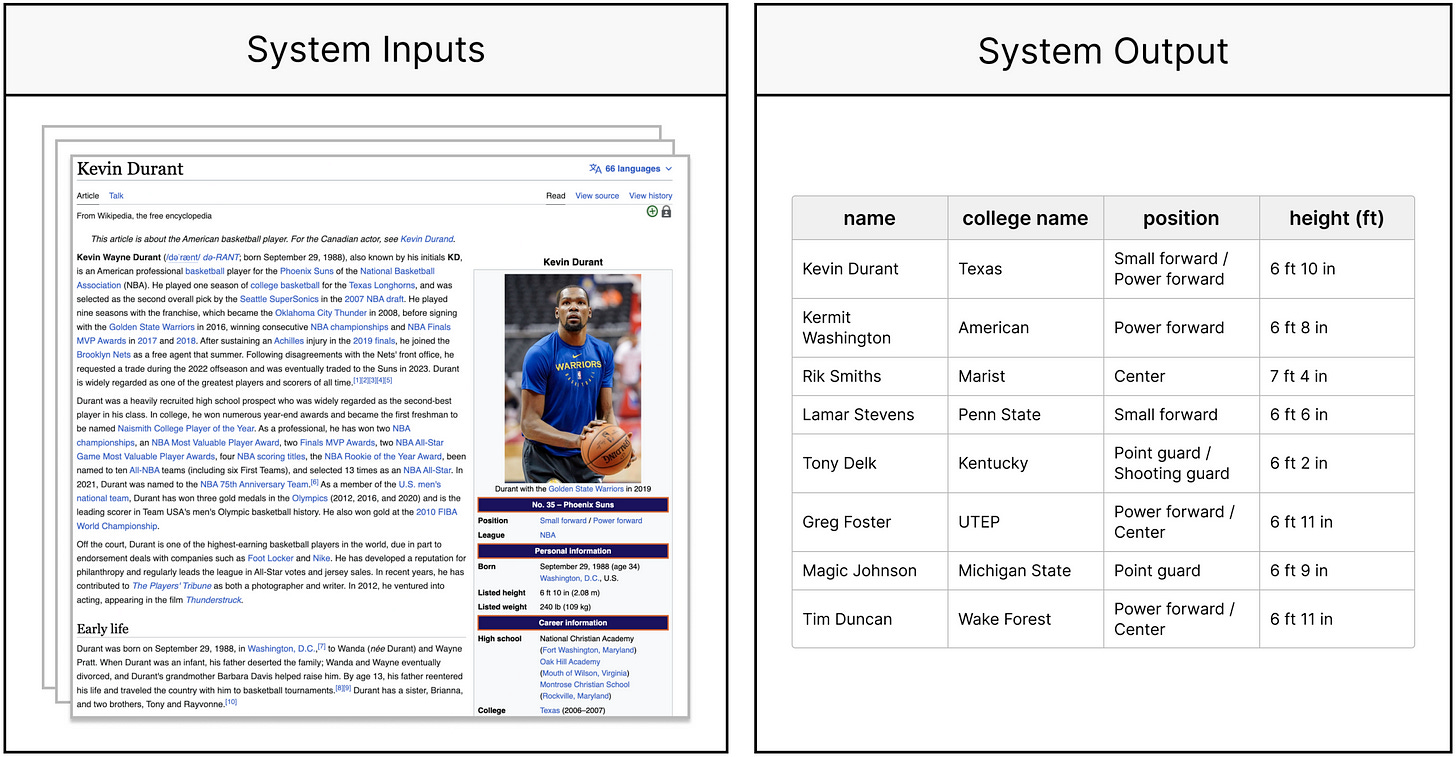
Evaporate-Code+是由斯坦福大学和康奈尔大学的研究人员开发的系统,它将一组半结构化文档作为输入,自动识别表格的重要属性/模式,提取值,并输出可查询的表格。在下面的图片中,您可以看到一个例子,系统被馈送了关于NBA球员的维基百科文章。然后,它自动识别出表格的属性——姓名、大学名称、位置、身高(英尺),最后,它用提取出的值填充了表格。
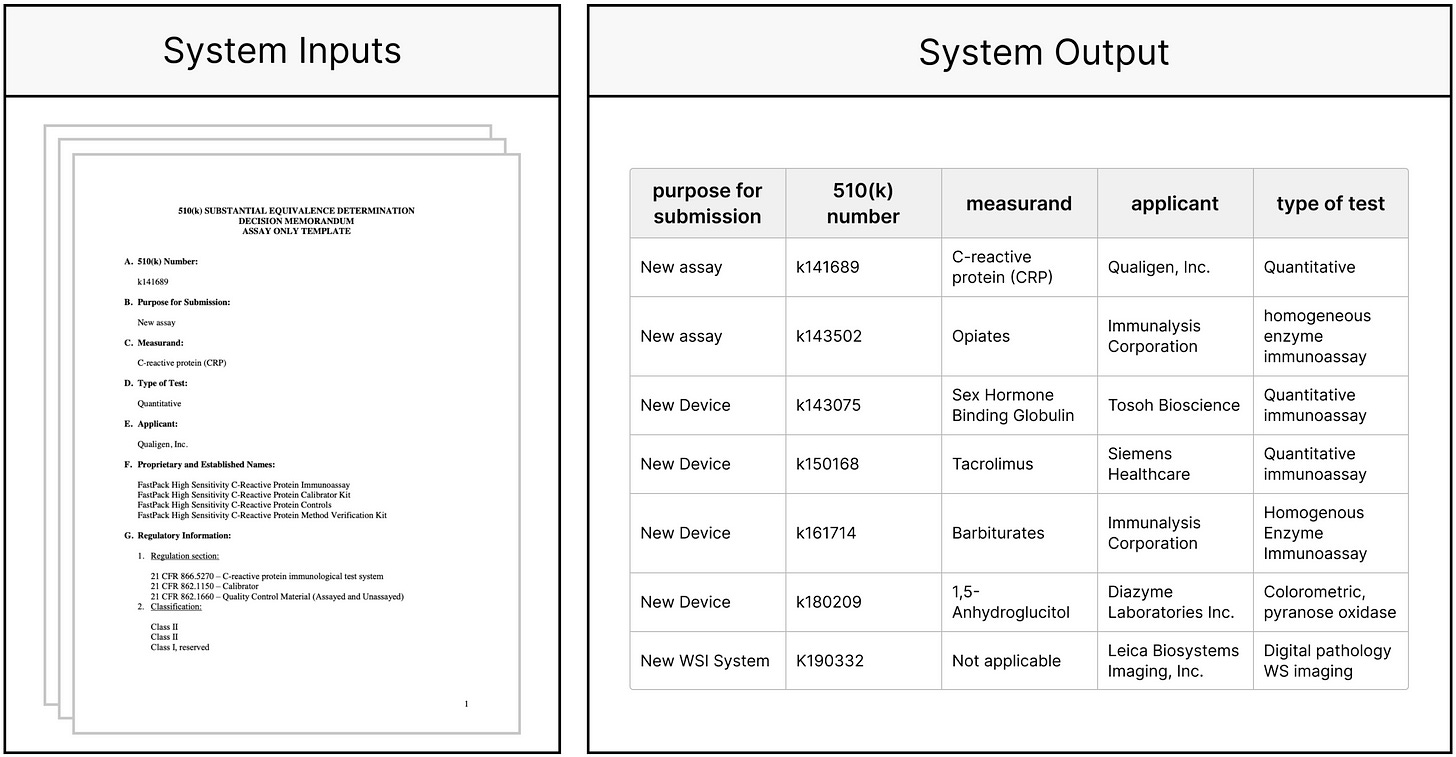
另一个例子涉及FDA 510(k)文件的收集,其中包含有关各种医疗设备安全性和有效性的政府审查。
那么,Evaporate-Code+是如何将文本转换为表格的呢?设计该系统的关键思想是,直接让LLM处理文档的成本很高,但可以产生很好的结果,而是让LLM生成Pythonic代码,然后用来处理文档的成本很低,但远非准确。以下是算法的大致概述:
-
识别模式/属性。
-
选择一小部分文档。
-
通过遍历每个选定的文档并提示LLM从文档中提取最有用的属性来生成候选属性。
-
将提取的属性的并集给LLM,并指令其识别最有用的属性。
-
-
提取值以填充表格。
-
提示LLM综合许多候选的Pythonic函数,然后将其应用于文档以提取值。
-
由于一些候选Pythonic函数在不同文档上的表现比其他函数更好,因此使用弱监督算法。该算法在文档上运行每个函数,然后聚合函数的输出以产生正确的提取值。弱监督背后的思想是在多个噪声源的情况下获得准确的结果。 (附:作者在这一步骤中再次使用LLM,但他们仅在一小部分文档上应用它作为地面实况标签。)
-
下面是显示整个流程的图表:
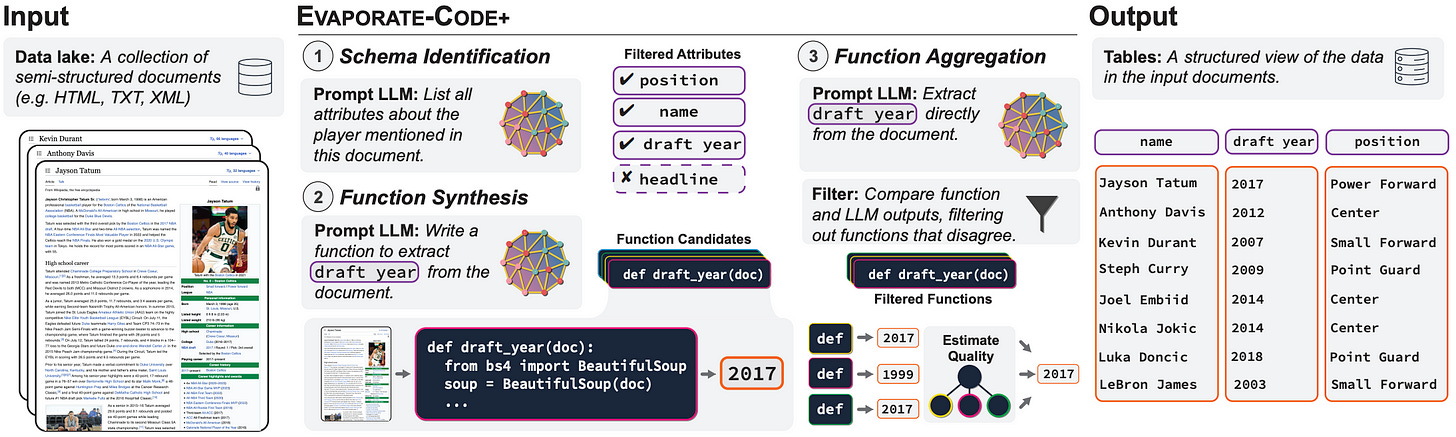
有趣的是,直接使用LLM(而不是生成Pythonic函数)直接提取值的简单解决方案,胜过SOTA基准系统。使用LLM在结果质量和普适性方面带来了巨大的好处,因为不需要进行特定任务的训练(作者没有微调LLM,而是使用了像OpenAI GPT-4这样的标准模型)。然而,直接使用LLM的成本是不可行的,因此Evaporate-Code+是一个在成本、质量和普适性三个属性之间找到平衡的解决方案。
#2. 从自然语言到代码(Khatry等人)
在微软的研究论文《从自然语言到代码:利用数据进行自然语言程序综合》中,研究人员提出了一个框架,将数据操作任务的自然语言(NL)描述转换为执行该任务的代码。他们声称这样的框架的主要动机是简化那些可能不熟悉数据科学和商业智能工具(如Pandas、SQL或Excel中使用的数据操作语言M)的人的工作。
所以,问题在哪里?为什么我们不能提供一个单一的提示让LLM生成代码完成任务,比如“将“Path”列中所有内容的结尾修剪一个字符”?问题在于,在创建最佳提示并要求LLM生成25个候选程序后,正确的解决方案被埋在了错误的候选者列表中的第10个位置。“LLMs的默认顺序表现不佳。”这里所说的“最佳提示”是指包括NL查询/任务、表的模式、表中的一些示例行以及一些带有相应代码解决方案的NL查询示例(少量提示)。下面是产生候选程序的框架的大致概要,使第一个候选程序很可能是正确的:
-
使用温度混合为LLM提供“最佳提示”生成候选程序。温度混合是作者提出的一种新技术,可帮助避免LLM生成的候选集中不包含正确程序的情况。这种技术涉及微调采样温度,LLM的一个超参数,用于控制生成输出的随机性。温度越高,下一次使用相同提示运行LLM时,输出就越有可能不同。作者声称,在代码生成的环境中,他们注意到了一个权衡:温度越高,生成的候选项越多,但是
top-1 的准确性会下降。 -
对于生成的每个候选项,计算平均对数概率分数。对数概率是LLM提供的一个值,它包含下一个标记的对数概率。对于语言模型中标记的对数概率越高,模型认为该标记是序列中下一个标记的可能性就越大。这是基于模型在训练期间学习有关单词和短语如何组合成语言的模式。要计算候选程序的分数,请取其标记的对数概率分数的平均值。
-
使用语义重新排序技术对生成的候选项列表进行重新排序。在输入数据集或其子集上运行每个候选程序,以获取相应的输出。执行语义过滤,包括删除执行失败的候选项。执行语义交错,包括将生成与某些更高排名的候选项相同的候选项向下移动,以增加前K个候选项的多样性。
上图显示了框架的体系结构。在这种情况下,LLM生成的候选程序列表显示在第2步中。正确的解决方案E最初位于列表的第五个位置,但在使用框架处理列表之后,正确的解决方案最终成为了第一个。虽然我们已经对框架进行了高层次的介绍,但值得注意的是作者的评论 - “与所有以前的工作的重要区别在于,我们的贡献不仅是经验性的,我们还为交错提供了理论上的理由。”
总结
每篇论文都有多个新颖贡献,但如果我们要总结这两篇论文的主要观点,那么如下:
-
LLM很好但直接处理数据很昂贵。
-
LLM不适用于生成数据操作代码,但运行生成的代码比运行LLM要便宜。
-
一种可能的解决方案是提示LLM生成多个候选程序,然后对候选者进行后处理以确定正确的解决方案。
-
对候选者进行后处理应该涉及数据环境,意味着在样本数据集上对候选程序的输出可以帮助找到正确的解决方案。
None