


大家好!欢迎来到最新一期的AI指南,这是一份编辑式的新闻简报,涵盖了2023年4月份在AI研究(特别是这一期!)、产业、地缘政治和初创企业方面的重要发展。非常抱歉邮寄这一期的延迟了——最近AI领域非常热闹……我们已经拥有了超过22,000个订阅者,感谢你们的阅读!在我们开始之前,我们有几个新闻要告诉大家:-)
感谢上个月参加我主持的纽约和旧金山 LLM最佳实践聚会 的大家!你可以阅读我的朋友路易斯·科佩的
这里 进行学习总结,也可以观看这个1分钟视频 感受旧金山聚会的氛围。6月23日,我们将在伦敦举办第七届 研究和应用AI峰会,演讲嘉宾包括Intercom、Northvolt、Meta、Cruise、Roche/Genentech、Oxford等。请在
这里 进行注册,我们将很快发布门票链接。Air Street职业机会:如果你或你的朋友对开发者/ ML关系、领导我们的工作来构建AI社区、综合和分发最佳实践以及使用最新工具构建新的AI产品特别感兴趣,请在这里回复!
像往常一样,我们喜欢听取你们的想法和所做的事情,只需回复或转发给你的朋友即可:-)
🌎 AI的(地缘)政治
自OpenAI发布GPT-4并且ChatGPT的使用情况似乎非常惊人,已经过去了2个月。与此同时,对于监管、保障和保护消费者数据的呼吁越来越高,越来越关注GPT等模型。拜登总统对他的科学技术顾问委员会表示,“科技公司有责任确保他们的产品在发布之前安全。”当被问及“拜登总统,您认为AI很危险吗?”时,他回答说:“尚未可知。可能会有危险。”在5月份,美国主要AI技术公司的CEO,包括谷歌、微软、OpenAI和Anthropic,将与副总统卡玛拉·哈里斯会晤,讨论AI和安全问题。
我们的AI报告合作者Ian Hogarth在英国《金融时报》上发表了一篇题为《我们必须减缓追求类神AI的竞赛》的文章,提出了一个减缓AI发展动态的方案。正如我们在2021年的报告中所指出的那样,模型能力的投资远远超过了理论、可控性和系统的对齐方面的努力。虽然我不认为AGI会导致我们所知道的人类生命的终结(或类似的论点),但我确实相信,正如任何强大的技术一样,将其以可靠、健壮和安全的方式传递是非常重要的。借助神灵、生命和生计的损失,这不是实现务实结果的有效途径。例如,欧盟立法者在开发系统时必须或不得生产基础模型和通用AI模型(真正的区别是什么?)时,现在正在进行区分,以在欧洲市场上销售其解决方案。
今天的系统仍然有很多需要我们去学习的地方。事实证明,LLMs可能存在更基本的对齐问题:“对于任何具有被该模型展示的有限概率的行为,都存在可以触发该模型输出此行为的提示,其概率随提示长度的增加而增加。这意味着,任何减弱非期望行为但未完全消除它的对齐过程,都不能抵御针对性的提示攻击。”
在英国,政府宣布成立了一支1亿英镑的基础模型特遣队,以“确保主权能力和广泛采用安全可靠的基础模型,帮助英国在2030年成为科学和技术强国”的目标。接下来的情况让我们拭目以待,我不太确定。我怀疑他们可能涉及的一个主题是大规模数据许可证用于模型训练。例如,BBC是否可以开放其媒体档案以换取收入进行培训?我们在去年的AI报告中就做出了这一预测,即Reddit或Getty等内容所有者将转向企业许可证,以便在其语料库上进行大规模训练。Reddit现在正在朝着这个方向发展。
与此同时,印度的电子和信息技术部确认,政府“不考虑在该国制定法律或管制AI的增长”。相反,印度似乎正在倾向于启用AI发展的优势:“印度政府认为AI是该国和技术行业的重要战略领域。它进一步认为,AI将对企业和政府的增长产生动能,并采取了所有必要的政策和基础设施措施,以发展该国强大的AI行业。”
LLMs也正在进入国防领域。一方面,Palantir展示了在其AI平台中使用LLMs作为战场助手的功能。该系统可以接收指令,在战场上指挥资源并处理涉及机密网络和设备的情报。与此相关的是,海军陆战队大学和Scale AI的团队为针对对手的军事规划量身定制了一个LLM。他们能够加载对手的教义、开放源情报和威慑文献,并随后提出像“什么是联合封锁?”到“国家X如何使用柴油潜艇?”等问题。用户感觉该系统“在帮助学生回答与教义相关的问题方面表现出色,有助于制定对手的行动方案。”
None🏭 大科技公司
现在有很多关于AI中的护城河的文章 - 哪些公司拥有护城河,它们来自哪里?首先,谷歌的一篇泄露的博客文章概述了他们的业务(以及OpenAI的业务)在AI中没有护城河,开源是关键。像“与开源直接竞争是一个失败的主张”和“我们需要他们比他们需要我们更多”之类的声明设定了基调…“谷歌应该成为开源社区的领导者,通过与而非忽视更广泛的交流合作来带头。这可能意味着采取一些不舒适的步骤,比如公布小型ULM变体的模型权重。这必然意味着放弃一些对我们模型的控制权。但这种妥协是不可避免的。我们不能希望既推动创新又控制它。”
我的看法是不要过于强调护城河的存在或不存在。一切都发展得太快了(请参见斯坦福的生态系统图表,用于跟踪模型、数据集和应用程序),这导致长期内高变异性。高性能模型背后的秘密或技巧很难在这个特别不稳定的环境下保密 - 在这里,开源胜出。另一种看法是,高价值(通常也更高风险)的任务将孕育出其专门的AI模型(和系统),而较长尾的任务可以由更大的模型服务。相反,让我们回到基础:找到一个用户问题并提供一个真正强大的解决方案。这就是Replit如何处理他们的代码生成LLMs的方法,这些LLMs支持他们的目标帮助任何人构建软件。从长远来看,我的观点是,最终的护城河之一是“我不会因为购买XYZ而被解雇”。一家企业必须尽一切努力成为XYZ,无论是通过更好的技术、分销、品牌、定价还是其他方式。
谷歌的另一个重大新闻是将谷歌Brain(主要在旧金山)和DeepMind(主要在伦敦)合并(重新)组成由Demis领导的谷歌DeepMind单一实体,并由Jeff Dean担任首席科学家的角色。该领域的许多人认为这一举措表明该公司非常认真地与OpenAI等竞争。我同意,尤其是更加集中、组织有序的团队往往能够胜过其同行(参见:5年的GPT进展)。
🍪 硬件(有些类似)
自动驾驶试验继续向前推进。在英国,Wayve已经开始自动化地从Asda送货,驾驶员后面有一个人类安全驾驶员,他们在伦敦繁忙的街道上行驶。在旧金山,Cruise一直在为消费者提供夜间驾驶服务,没有安全驾驶员,感觉已经有一段时间了。他们正在扩大该服务到休斯顿和达拉斯,并正在追求加利福尼亚的扩大区域。我在2022年12月底使用了该服务,对其质量感到惊讶(感谢,Oliver Cameron!)。上个月,我在Waymo上进行了白天的乘车,同样感到印象深刻。说真的,我认为自动驾驶服务已经来了,并且将会工作,尽管这个领域的报道都很不乐观。实际上,Oliver最近在推特上发表了一系列关于自动驾驶7年进展的推文,真正展示了机器学习的积极影响。
与此同时,谷歌发布了一份关于其TPUv4系统的技术报告,与NVIDIA的A100和Graphcore的Bow相比,表现良好。Elon的X Corp(拥有Twitter的母公司)购买了10,000个NVIDIA GPU,以支持他的人工智能工作。
🎁 接下来是什么?
目前,AI Twitter上的自主代理(AutoGPT,BabyAGI等)是重点。这些系统基本上将LLM链接在一起,将它们用作“代理人”,可以制定逐步解决任务的策略,并使用工具执行它们。这几乎是许多人设想的软件自动化重复任务的梦想。虽然这些开源库引起了人们的想象力,但我相信魔鬼很可能在长尾(de)中。从我的自身经验来看,如果一个系统在1-2次尝试内言过其实,我会失去信任并回到我现有的解决方案。可以说,虽然自主代理减少了构建自动化系统所需的知识,但它们需要在出厂时具备健壮性和可靠性。我们还没有到达那里,但我正在关注这个领域。
🔬 研究
Meta发布了一个名为“Segment Anything”的大规模项目,其中包括在1100万张图像数据集上发布了10亿个分割掩模以及一个名为SAM的分割模型。这个项目可以用三个点来概括:
任务定义:可提示的分割。该项目的目标是构建一个模型,可以在任何文本提示的情况下分割图像,即使它在训练数据集中不存在,即零样本泛化。
模型:模型需要支持灵活的提示,实时计算掩模以供交互式使用,并且需要具有歧义感知能力。满足这些约束的模型架构非常简单:它们使用图像编码器(视觉变换器-ViT)计算图像嵌入,使用文本编码器(CLIP文本编码器)进行提示嵌入,然后将组合嵌入馈入预测分割掩模的掩模解码器。拥有单独的图像编码器的好处是,可以重用图像嵌入以进行其他提示。这对于交互式使用尤其重要,因为人们通常会希望调整提示以获得更好的分割结果。他们通过训练以预测相同提示的多个地图来处理歧义性。
数据集:与文本不同,分割掩模在网络上并不大量存在。建立分割数据集可能很快就会变得非常昂贵(请问任何计算机视觉公司雇用注释者来构建其图像分割数据集)。为了解决这个问题,研究人员通过模型循环注释的方式开发了一个“数据引擎”。数据引擎具有3个逐渐增加的自动化阶段:
“(i) SAM协助注释者进行分割,(ii) SAM通过提示可能的对象位置自动生成掩模,注释者专注于注释剩余对象,帮助增加掩模差异性,(iii) SAM通过前景点的正则网格进行提示,平均每个图像产生约100个高质量掩模”
Meta在23个分割任务上测试了SAM,并报告了性能,通常只略低于手动注释的图像。值得注意的是,他们展示了通过提示工程,SAM可以用于其他任务,包括边缘检测、目标提议生成和实例分割。Meta发布了针对研究人员的SA-1B数据集,并开源了SAM。这是一个真正了不起的项目。后续(和并发的工作)已经在进行中:
Segment Everything Everywhere All at Once :来自威斯康星大学麦迪逊分校、微软和香港科技大学的并发工作。Personalize Segment Anything Model with One Shot :允许用户通过给SAM提供额外的参考掩模来更好地定制特定视觉概念的SAM。Track Anything: Segment Anything Meets Videos :将SAM和XMem(视频对象分割模型)结合起来进行实时对象跟踪。Segment Anything in Medical Images
现在是我们定期检查变压器输入长度的时间:
-
Unlimiformer: 无限长度输入的长距离变压器 ,卡内基梅隆大学。为了避免编码器-解码器模型对输入的二次依赖关系,CMU的研究人员建议(i)选择一个较小的期望上下文长度,(ii)将一个可能很长的序列分成这个长度的块,(iii)使用数据存储中的编码器存储每个编码的块,(iv)在每个解码步骤中,使用k-NN搜索查询数据存储。通过对注意力的巧妙重新制定(如果您对此感到好奇,请查看本文的2.3节),可以高效地完成此操作。这使模型能够对长达350k个标记输入进行总结。他们方法的一个不错的特点是,它可以用于现有的编码器-解码器模型,如LongFormer。
-
使用RMT将变压器扩展到100万个标记及以上 ,DeepPavlov、AIRI、LIMS。在训练过程中,将长达4096个标记的序列分成7个512个标记的段。这些段依次通过增加全局记忆标记的变压器块进行馈送,这与常规循环神经网络所做的一样。在推断(其中不进行记忆和计算密集的反向传播)期间,可以对长度超过2M个标记的序列执行相同的过程。如果您读得太快,您会认为变压器的昂贵的长距离依赖已经解决了。但这篇论文实际上是将变压器的力量带到循环神经网络中。循环神经网络的一个优点(如果正确实现)是不会忘记早期的序列。变压器的一个优点是,只要它不太长(否则会变得太昂贵),它就能够提高对任何单词序列的语言理解能力。因此,该模型将能够识别出特定事实所在的段,并对它们进行合理分析,但它将无法连贯地使用跨越整个文本的所有标记(超过2M个标记)来生成答案。
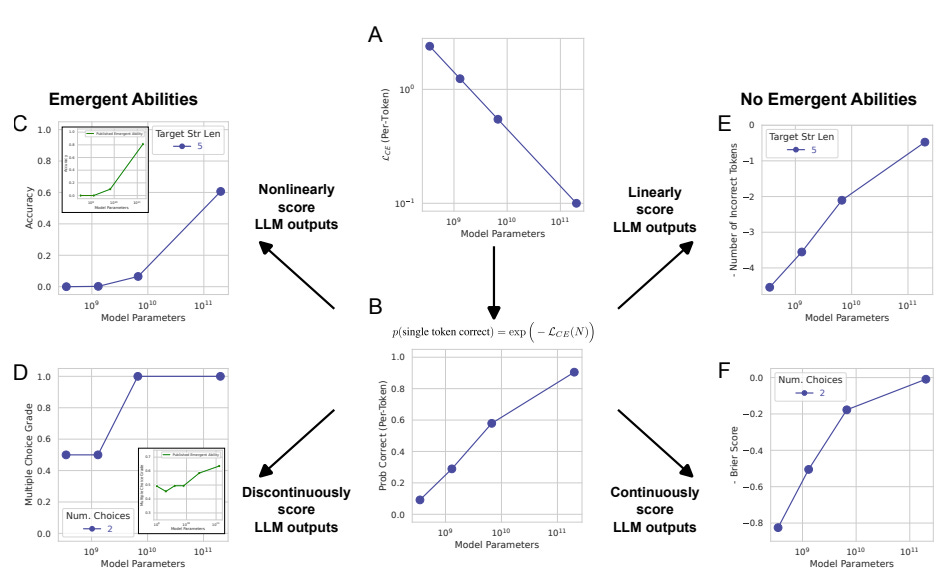
大型语言模型的新兴能力是幻觉吗?斯坦福大学。 "我们的替代方案表明,现有的新兴能力声明是研究人员分析的产物,而不是模型在特定任务上随着规模的变化而发生的基本变化。" 作者们提供了证据,表明新兴能力不是规模化AI模型的基本属性。他们认为,LLM性能的急剧提高和其不可预测性是“研究人员选择了一种非线性或不连续地扭曲每个标记误差率的度量标准,部分原因是测试数据太少,无法准确估计较小模型的性能(从而使较小模型似乎完全无法执行任务),部分原因是评估了过少的大规模模型”。
使用GPT-4进行指令调整,微软。选择任务T,使用巨型模型代替模型M。看巨型模型在T上击败每个M。在这里,巨型模型={GPT-4},T={生成用于微调语言模型的指令}。请记住,使用人类编写的指令对自我监督的语言模型进行微调,在训练GPT-3.5和其他最先进的语言模型方面至关重要。斯坦福的Alpaca(以及其他人)表明指令编写过程可以委托给非常好的LLM。微软的研究人员在这里展示,“使用GPT-4生成的52K英文和中文指令遵循数据,对新任务的零样本性能优于以前最先进模型生成的指令遵循数据。”
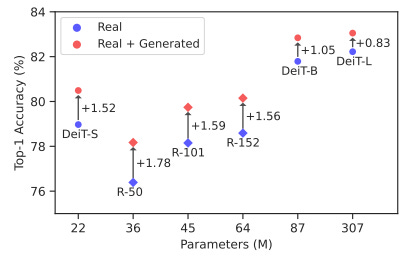
谷歌研究表明从扩散模型中生成的合成数据可以提高ImageNet分类准确性。现在我们可以使用巨大的模型={谷歌的Imagen}和T={生成合成图像来训练模型}。生成合成图像——以及更一般的合成数据——来训练计算机视觉模型一直是机器学习研究者的一个早期幻想,但现在已经成为现实。在这里,谷歌研究人员展示了大规模的文本到图像扩散模型可以生成类别条件图像(即从给定数据集中给定标签的图像),这导致了比仅使用真实ImageNet训练的强ResNet和Vision Transformer基线更显着的ImageNet分类准确性提高。
Align your Latents: 高分辨率视频合成与潜在扩散模型,NVIDIA。由于视频合成是一项特别资源密集型的任务,潜在扩散模型(在潜在空间而不是像素空间训练扩散模型)是一个自然的选择。在这里,NVIDIA的研究人员使用潜在扩散模型作为骨干图像生成模型,然后通过在潜在空间扩散模型(LDM)中包括时间维度并对视频进行微调,将图像生成器转换为视频生成器。还向上采样器(从潜在空间到像素空间)添加了时间维度以恢复实际图像。可以简单地使用预训练的LDM,如稳定扩散,仅训练时间对齐模型。结果,他们可以生成分辨率高达1280x2048的短视频。样本质量真的非常惊人。
我们还关注以下内容:
扩散模型解锁上下文学习 ,德克萨斯大学奥斯汀分校,Microsoft Azure AI。给定一对图像(通常是输入和期望输出)和文本指导,模型自动理解任务并在新的图像查询上执行它。使用深度强化学习为双足机器人学习敏捷足球技能 ,DeepMind。在仿真环境中训练人形机器人使用深度强化学习进行简化的1v1足球比赛。培训是在模拟中完成的,然后在真实机器人中进行零样本转移。机器人仅针对得分进行了优化,但最终“行走速度提高了156%,起身时间缩短了63%,踢球速度比脚本基准快24%。”使用强化学习实现蛋白质架构的自上而下设计 ,华盛顿大学。使用自上而下的RL代替自下而上的新颖设计方法来模拟多亚基蛋白质组装中自然发生的功能演化选择。
CodeGen2:关于编程和自然语言培训LLMs的经验教训 ,Salesforce Research。Salesforce的开源编程语言模型的第二代版本发布。HuggingGPT:使用ChatGPT及其Hugging Face朋友解决AI任务 ,浙江大学和微软亚洲研究院,以及TaskMatrix.AI:通过连接基础模型和数百万个API完成任务 ,Microsoft。在这两篇论文中,作者探讨了如何使用LLM作为专业模型生态系统顶部的推理代理和控制器。用户输入问题,代理人使用所述下游模型的组合来解决问题。盲目、随机的心脏功能评估试验 ,斯坦福和锡达西奈医院。这项临床试验表明,AI辅助分析心脏扫描图像可以节省临床医生的时间,而由AI生成的评估结果与未使用AI的评估结果无法区分。Vicuna:一个开源的聊天机器人,使用90%* ChatGPT质量令GPT-4印象深刻 ,加州大学伯克利分校,UCSD,CMU,MBZUAI。这项工作通过使用聊天GPT从sharegpt.com的70,000个用户对话fine-tuning LLaMA基础模型来开发一个13B参数的ChatGPT样式系统。生成代理人:人类行为的交互模拟器 ,斯坦福和谷歌。这项工作创建了学习The Sims并在那个世界中运行的代理人——它们展示了代理人如何模拟可信的类人行为。重新思考AI评估结果的报告 ,剑桥和其他。这篇文章正确地推动社区报告更精细的度量标准,记录所有评估结果,并创建测试特定能力的基准。
利用学习到的表面指纹,EPFL和牛津大学进行蛋白质相互作用的全新设计。该工作采用几何深度学习来设计一个“以表面为中心”的方法,从而捕捉分子识别的物理和化学决定因素,实现了对蛋白质相互作用以及更广泛的具有功能的人造蛋白质的全新设计。
None None💰创业公司
融资亮点
LangChain是一种流行的开源框架,用于构建基于LLM的应用程序,引领了一轮1000万美元的种子轮融资,由Benchmark领投,几个月后又引领了一轮2-2.5亿美元估值的A轮融资,由红杉资本领投。
Covariant是电子商务仓库拣选和放置机器人,除了在2021年筹集了8000万美元外,还扩大了C轮融资规模,筹集了另外7500万美元,由现有投资者领投。
Enveda,从植物中提取分子的药物研发公司,通过Kinnevik和KKR的额外资本将其B轮融资扩大至1.19亿美元。
Harvey,一家基于LLM的法律软件公司,通过Sequoia领导的A轮融资筹集了2100万美元。
OpenAI以27-29亿美元的估值完成了一次3亿美元的股份销售,投资者包括Sequoia,Andreessen Horowitz,Thrive和K2 Global。
Pinecone,一家热门的向量数据库公司,通过7500万美元的估值筹集了1亿美元的B轮融资。
Weaviate,另一家向量数据库公司,通过Index领导的5千万美元的B轮融资筹集了5000万美元。
Replit,协作式软件开发和教育工具,通过a16z Growth领导的9700万美元的融资筹集了11.6亿美元的估值,以扩展其人工智能能力(如上所述!)。
Veo Robotics,一家提供机器人和人类在仓库中共存的机器人安全公司,筹集了2900万美元的B轮融资,其中包括亚马逊的资本。
AlphaSense是一家金融数据公司,最新获得了1亿美元融资(此前已宣布完成2.25亿美元B轮融资),由CapitalG领投,旨在加快AI技术的融合。
退出
近期没有特别引人注目的退出事件!投资则更加活跃 :-)
---
以上是本期内容,谢谢收听。
作者:Nathan Benaich, Othmane Sebbouh,2023年5月21日
Air Street Capital | 推特 | 领英 | AI报告 | RAAIS | 伦敦.AI
Air Street Capital是一家投资于AI-first技术和生命科学公司的风险投资公司。我们是一支经验丰富的投资者和创业者团队,总部位于欧洲和美国,共同热衷于与创业者一起开展公司建设旅程。
