


来自一个世界的问候……
我们通过SuperCLUE提高自己,而不是用超级胶水粘东西。
如往常一样,所有过去期刊的可搜索档案在这里。请在此处订阅以支持ChinAI,采用类似于《卫报》/维基百科的小费模式(每个人获取相同的内容,但可以支付的人支持全面访问和超棒ChinAI贡献者的补偿)。
特别报道: SuperCLUE基准排名
背景:来自CLUE的团队是一个中文理解评估基准,测试语言模型的能力,而SuperCLUE是一个更全面的基准,于5月9日发布。 SuperCLUE团队最近测试了来自中国和国际实验室的10个模型,涵盖了三个不同的维度:1)基本能力,如逻辑推理和编码; 2)专业能力,如物理知识;和3)中文特有的能力,如成语和文学知识。
每个维度都包含不同的子类别。以下是一个中文成语子类别的SuperCLUE测试问题示例:
以下哪个句子中成语使用不正确?
A. 这个项目时间紧任务重,大家都在马不停蹄地奔波劳碌。
B. 他常常口是心非,让人难以相信他说的话。
C. 两人是同学三年,一直保持着良好的关系,相互尊重、相敬如宾。
D. 当地突发大火,整个村庄都鸡犬不宁,局势十分危急。
*成语“相敬如宾”在C语言中被错误使用。
关键结论:根据SuperCLUE排行榜,国际模型(如GPT-4)与中国大型语言模型之间仍存在较大差距。GPT-4在SuperCLUE上的总分(76.67)比表现最佳的中国模型——科大讯飞的SparkDesk模型[星火认知大模型]高23分,后者的得分为53.58分(见下图中的排名列表)。
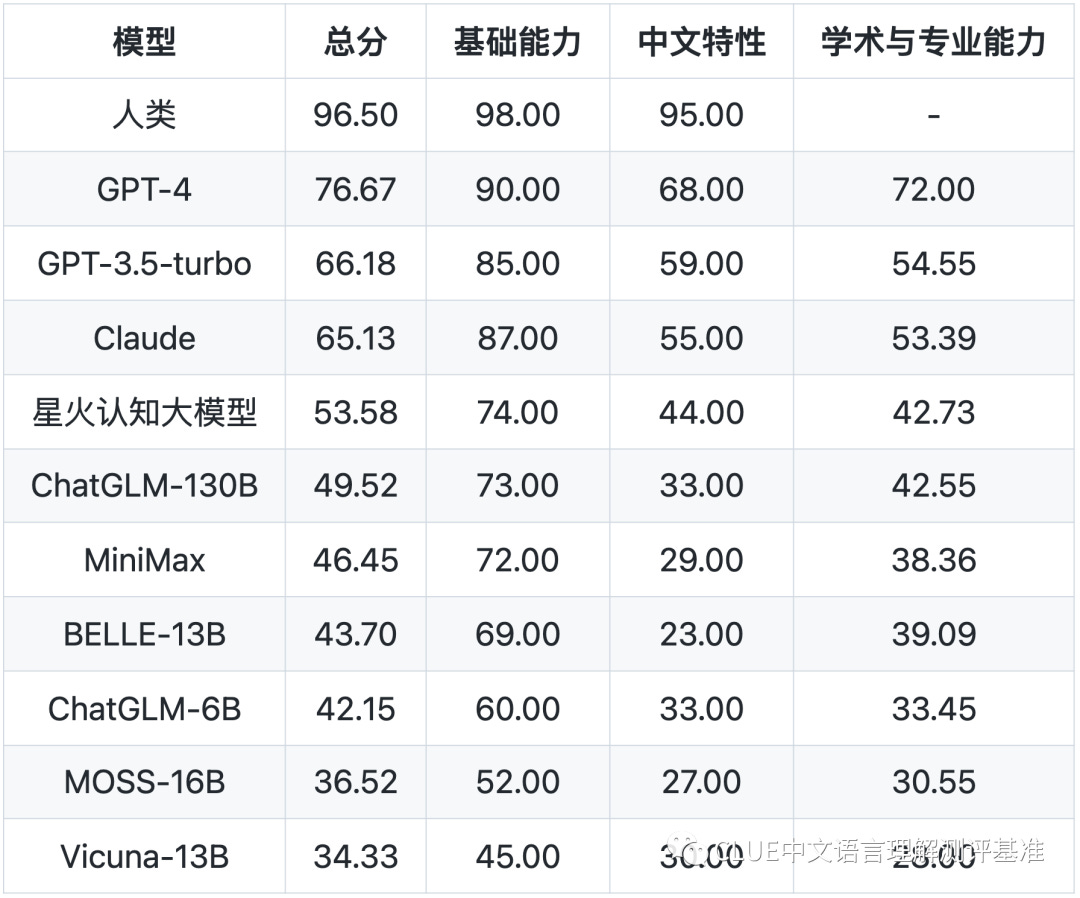
NLP(自然语言处理)中的“L”很重要吗?SuperCLUE团队仍然认为需要针对中文任务性能进行优化的模型。
他们的理由是:Vicuna-13B是一个由美国大学的研究人员推出的开源ChatGPT替代方案,是一个相当不错的语言模型,但在中文语言特征测试中排名较低。由中国组织开发或在中文语言数据集和任务上接受了训练的模型在这个维度上的表现远远超过了Vicuna-13B。
然而,我仍然不能理解的是:ChatGPT在中文方面表现如此出色,尽管它几乎完全使用英文进行训练。OpenAI研究员Jan Leike也不知道为什么。
注意事项
我认为像SuperCLUE这样的指标是传播大型语言模型信息健康生态的指标。然而,基准测试并非没有缺点。一些人工智能基准测试,包括英语SuperGLUE基准测试,已经达到了
饱和 。这可能是因为实验室优化了基准测试而不是这些指标所要衡量的内容。根据我和他人合著的
GovAI报告 关于中国大型语言模型景观,我认为百度的Ernie模型是最强的中文LLM,所以看不到它们在这个列表上有些令人困惑。同样令人困惑的是:百度的Ernie模型已经使用了CLUE和FewCLUE(CLUE的少样本学习评估版本)作为基准测试,因此我希望它们也能接受SuperCLUE测试。更加神秘的是:似乎早期的SuperCLUE排行榜将百度的ErnieBot排在最后。还有一些流言蜚语 认为SuperCLUE团队中的一名成员与科大讯飞的联合实验室有所联系。我们将在下个月回来看看这个问题,因为SuperCLUE基准测试计划每月更新一次,因此下一个版本可能会包括百度的ErnieBot。我要说的是,这使我对科大讯飞的SparkDesk模型非常强大进行了一些更新。
我们在最近几个全文翻译的Google文档中进行了一些非常好的讨论,我知道一些读者熟悉英语的SuperGLUE基准测试,因此我特别欢迎你们在完整翻译中进行注释:中国通用大型模型评估基准SuperCLUE更新,增加了清华和克劳德GLM 1000亿(参数)模型。
ChinAI链接(四个推荐)
必听:我在ChinaTalk Podcast上的访谈
非常感谢Jordan Schneider邀请我参加最近一期的ChinaTalk Podcast,谈论我的最新发表的扩散缺陷论文和书稿。曾服务于白宫科学技术政策办公室和DeepMind的Teddy Collins也为访谈做出了很大贡献。如果你有兴趣深入了解,OpenAI的政策研究负责人Miles Brundage发布了一系列见解深入的Twitter线程,反驳了我们讨论的一个主题——通用技术扩散的缓慢速度。
必读:中国智慧城市与地缘政治的未来
德国对外关系委员会的研究员Valentin Weber撰写的一篇关于中国城市治理中应用人工智能的报告,该报告强调了中国公司在海外建造的智慧城市存在的一些安全风险。
必读:熟悉性在AI采用中既有信任又有轻蔑
Mike Horowitz、Lauren Kahn、Julia MacDonald 和 Jacquelyn Schneider 在AI & Society杂志上发表了一篇新文章,探讨了熟悉度对AI采用的影响:
那些对AI和类似技术熟悉并具备专业知识的人比那些对该技术了解有限的人更有可能支持我们测试的所有自主应用(除了武器)......然而,熟悉度也有两面性;如果技术自动化了他们已经熟悉的任务,个人也不太可能支持AI启用的技术,尤其是直接应用到他们的生活中。
必读:GPT就是GPT:对大型语言模型劳动力市场影响潜力的早期研究
Tyna Eloundou、Sam Manning、Pamela Mishkin 和 Daniel Rock(来自OpenAI、OpenResearch 和UPenn的研究人员)发布了一篇工作论文,探讨了生成式预训练转换器作为通用技术(GPTs)的潜在影响。他们发现:“大约80%的美国劳动力可能会受到LLMs引入的影响,至少有10%的工作任务受到影响,而大约19%的工人可能会看到至少50%的任务受到影响。”
感谢Nathan Labenz的推荐。
感谢您的阅读和参与。
这些是Jeff Ding(有时)每周翻译的关于AI和相关主题的中文思考。Jeff是乔治华盛顿大学的政治学助理教授。
查看所有过往期刊的存档,请点击此处,并请通过类似《卫报》和维基百科的小费模式订阅此处以支持ChinAI的运营(每个人都可以获得相同的内容,但那些能够支付订阅费用的人将支持所有人的访问)。
有任何建议或反馈?请通过chinainewsletter@gmail.com或者在Twitter上@jjding99与我联系。