论文地址:Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation
GitHub地址:https://github.com/rbgirshick/rcnn
-----------------------------------------------------------------------------------------------------------------------------------------------
图像分类,检测及分割是计算机视觉领域的三大任务。图像分类模型是将图像划分为单个类别,通常对应于图像中最突出的物体。但是现实世界的很多图片通常包含不只一个物体,此时如果使用图像分类模型为图像分配一个单一标签其实是非常粗糙的,并不准确。对于这样的情况,就需要目标检测模型。目标检测模型可以识别一张图片的多个物体,并可以定位出不同物体,它很多场景有用,如无人驾驶和安防系统等。
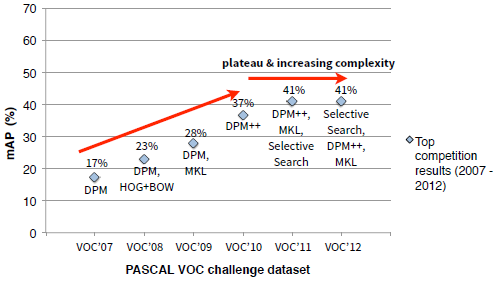
近10年以来,在视觉识别上大部分的方法还是基于SIFT和HOG特征的,从下图中可以看到,以手动提取特征为主导的物体检测任务mAP(物体类别和位置的平均精度)提升缓慢,瓶颈难以突破。
随着ReLu激励函数、Dropout正则化手段和大规模图像样本集ILSVRC的出现,Hinton及他的学生在2012年ImageNet大规模视觉识别挑战赛中采用CNN特征获得了最高的图像识别精确度。自此之后,卷积神经网络重新引起大家的重视,同时手工设计特征方式逐渐退出舞台。由Ross Girshick 在2014年CVPR提出的RCNN[1]算法将目标检测推向新的里程碑。RCNN是借助CNN强大的特征表达能力和SVM高效的分类性能来突破目标检测的瓶颈。作者在文章中注意有2个创新点 :
后续详细内容:https://blog.csdn.net/CAU_Ayao/article/details/90733885